承接昨天的code
為了怕忘記,先說明dls 是什麼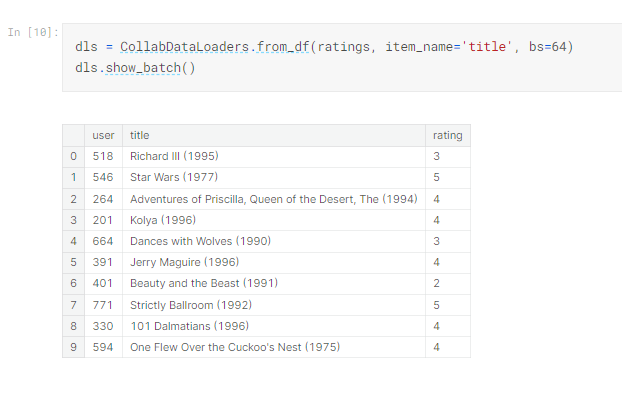
class DotProduct(Module):
def __init__(self, n_users, n_movies, n_factors):
self.user_factors = Embedding(n_users, n_factors)
self.movie_factors = Embedding(n_movies, n_factors)
def forward(self, x):
users = self.user_factors(x[:,0])
movies = self.movie_factors(x[:,1])
return (users * movies).sum(dim=1)
這個 class 的名字 "DotProduct" 代表了一個模型,用於電影推薦。它的主要功能是進行用戶對電影的評分預測,通過計算用戶嵌入和電影嵌入之間的內積。這個模型可以使用參數 n_users、n_movies 和 n_factors 來建立。當調用其中的 "forward" 方法時,它會接受一個包含用戶和電影信息的輸入張量 x,然後對這些信息進行嵌入,計算內積,最終回傳評分的預測結果。
現在只寫了forward ,後面應該還要補充其他方法
以下是使用這個類別建立一個物件,取名叫model,然後把他傳入fastai.Learner類別中建立Learner物件
取名為learn,然後跑5個epoch, learning rate設定為5e-3
model = DotProduct(n_users, n_movies, 50)
learn = Learner(dls, model, loss_func=MSELossFlat())
learn.fit_one_cycle(5, 5e-3)
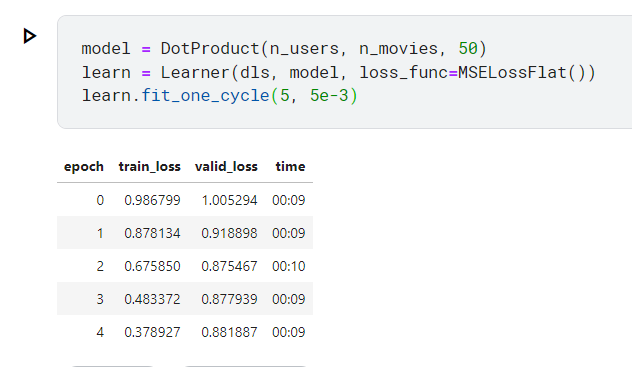
fit_one_cycle 我又忘記了,再註記一下:
1cycle policy 的學習率調整策略:
這個策略的主要思想是在訓練過程中逐漸增加學習率,然後再逐漸降低學習率,以加速模型的收斂,同時防止過度擬合。
通常包括以下步驟:
以較低的學習率開始訓練
然後逐漸提高學習率,直到達到一個最大值。
接下來,再逐漸降低學習率,直到訓練結束。
這種策略的目標是在開始時快速收斂,然後在訓練過程中進一步調整以提高模型的性能。使用 fit_one_cycle 方法,就可以輕鬆實現這種策略,而不必手動調整學習率。這也是與pytorchd的OneCycleLR最大差別
好這不是重點,因為我們其實是要看協同過濾是怎麼做的。
上這門課的問題就是初學者(像我),就會常常被小動作帶偏,而搞不清楚最終目標是什麼。
所以要練習看不懂的先搞懂這一大段的「目的」是什麼,先看效果,中間弄不懂的東西或是小技巧,等第二遍再來弄懂
那現在講師用自創的內積算法,做了一個model ,然後拿來跑,顯然結果不怎麼好
那該如何改進呢?
首先講師說到我們的模型,缺少了偏見這個參數
也就是說我們的編碼頂多可以說明這部電影多科幻,多老、動作成份有多少,而不能說明人們有多喜歡他,
一但有人特別積級評分,或是特別消積評分,可能會讓我們的模型有較大的偏差
所以這邊就要加入bias
所以我們的內積模型可以修改如下
class DotProductBias(Module):
def __init__(self, n_users, n_movies, n_factors, y_range=(0,5.5)):
self.user_factors = Embedding(n_users, n_factors)
self.user_bias = Embedding(n_users, 1)
self.movie_factors = Embedding(n_movies, n_factors)
self.movie_bias = Embedding(n_movies, 1)
self.y_range = y_range
def forward(self, x):
users = self.user_factors(x[:,0])
movies = self.movie_factors(x[:,1])
res = (users * movies).sum(dim=1, keepdim=True)
res += self.user_bias(x[:,0]) + self.movie_bias(x[:,1])
return sigmoid_range(res, *self.y_range)
可以看到user 多了bias,movie 也多了bias
還多了一個y_range表示模型的輸出應該落在的範圍,通常用於回歸問題。
forward 中,res 一樣要先做內建,但是最後再加上user 及movie 的bias
最後應用 sigmoid_range 函數,將輸出限制在指定的 y_range 範圍內,這通常用於回歸問題,確保輸出在合理的範圍內。
設定完再跑一次看看結果,有沒有更好?
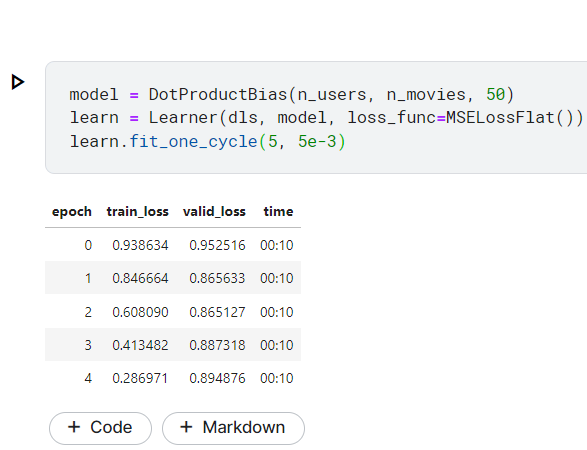
結果變更爛了!!
我們可以觀察,發現在train 的loss 持續下降,而valid 卻幾乎沒什麼降,最後反而上升
這可能存在潛在的過擬合現象。
所以這邊講師提供了一種方法來決解這個氣現象:權重衰減(weight decay)
也就是L2正則化
先來觀察一下為什麼要加入權重衰減
看一下以下的code 及圖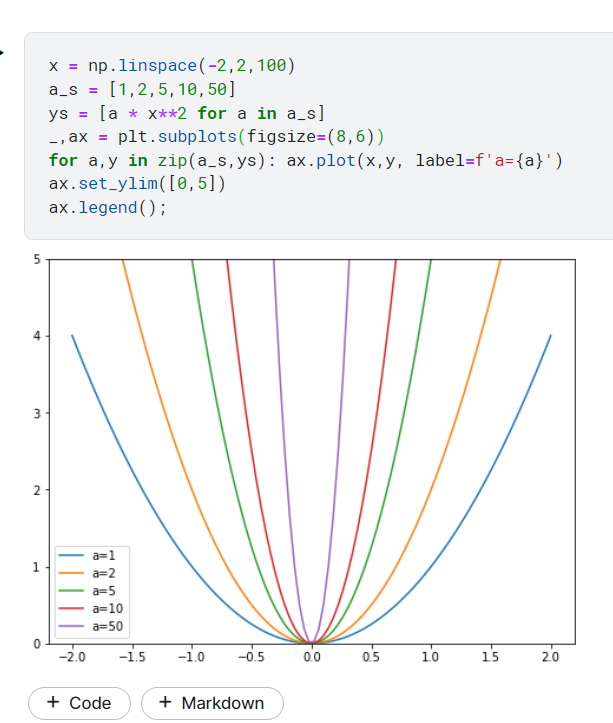
這張圖說明了如果在計算梯度時,沒有加入正則化的話
則這個受某係數影響很大,如圖中的a
a 越大則圖越窄,容易落入局部最小值
所以我此時我們加入一個「權重平方和」就可以改善此現象
loss_with_wd = loss + wd * (parameters**2).sum()
但計算平方的話蠻消耗資源,還好我們知道微分的話,指數會變系數剩到變數上,所以平方就會變成2x
parameters.grad += wd * 2 * parameters
看一下改進後的code 還有執行結果
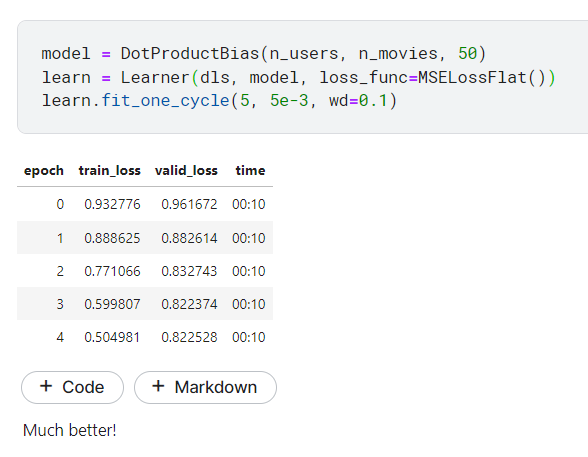
much better ? 我看來只有好一點🤣,但這個例子就到這邊。顯然我們還有很多可以改進的地方
接下來就要講 Creating Our Own Embedding Module 了,但這就到另一個影片去了
下一篤待續


 iThome鐵人賽
iThome鐵人賽